
If you are an avid reader of our blog then you might have already read about our article on spaCy library. It is used for performing various Natural Language Processing tasks.
There is another Python library TextBlob which is also used for processing textual data.
You might be wondering that if there are already libraries like NLTK and spaCy then why do we need TextBlob.
NLTK and spaCy Library are good libraries for performing Natural Language Processing tasks. But when it comes to NLU (Natural Language Understanding) which is a subset of NLP we need to work on unstructured data.
Both NLTK and spaCy are not able to perform in this scenario and thus TextBlob library comes under the spotlight. TextBlob is designed to handle both structured and unstructured forms of data.
NLU is basically performed to convert as much unstructured data into a structured form. Semantic parsing, Noun Phrase Extraction, Sentiment analysis are some of the examples of Natural Language Understanding.
In this article, we will be looking at Sentiment Analysis and how we can perform a Simple Analytics process with the TextBlob library.
What is the Sentiment Analysis?
Sentiment Analysis is a step-based technique of using Natural Language Processing algorithms to analyze textual data.
With the help of Sentiment Analysis using Textblob hidden information could be seen. This information is usually hidden in collected and stored data.
The analysis can show how positive or negative the text data is. There are many practical applications for this process. For example, These reports could help companies in creating customer-oriented strategies.
With the enhancement in Artificial Intelligence algorithms, it is much easier now to handle and study textual data. Moreover, these algorithms are getting high accuracy rates for their assumption of sentiments related to data.
Another major example of using Sentiment analysis is in Social Media channels. Platforms like Facebook, Twitter are using this technique for preventing the spread of fake and hateful news.
Factors Related to Sentiment Analysis
You already have the picture in your mind that what is Sentiment Analysis now. Let us move to the factors through which an algorithm reports the sentiment from any textual data.
There are three main factors:
1. Polarity
The polarity defines the phase of emotions expressed in the analyzed sentence. It ranges from -1 to 1 and goes like this:
- Very Positive
- Positive
- Neutral
- Negative
- Very Negative
On account of polarity, the emotion and sentiment of the writer can be easily described. For example, a person has written a review for some hotel as “Very bad service and staff”. Suppose the polarity of this sentence would be -0.56.
It is clear from the values that it is a negative emotion and against the brand image of the Hotel. This way polarity could easily determine the end sentiment.
2. Subjectivity
Polarity alone is not enough to deal with complex text sentences. Sometimes the sentence needs more attribute analysis to check whether it is describing features or opinions on some object.
For example, there are two sentences:
- This pizza has 6 slices.
- This pizza tastes very good.
In the first sentence, we have provided pizza with an objective approach and described its features. On the other hand, the second sentence provides an opinion based on how the person found the pizza to be.
Subjectivity helps in determining the personal states of the speaker including Emotions, Beliefs, and opinions. It has values from 0 to 1 and a value closer to 0 shows the sentence is objective and vice versa.
3. Intensity
Along with the polarity and subjectivity, another important factor is intensity. It defines how strong or weak the emotion is with respect to the context.
It contains the following range:
- Strong
- Medium
- Weak
- Neutral
With the help of intensity values, deeper insights into the expressions could be conveyed. For example, the review can go from “This hotel is good.” to “This hotel is the best”.
4. Author
The person who has the ownership for that text or who has written the text content. The content may be a review, conversation, social media chat, feedback, or response. This helps in managing a structured way of assigning expressions to a single entity.
Now as we have seen the factors of Sentiment analysis we will be looking at the TextBlob library.
What is the TextBlob Library?
TextBlob is an open-source python library used for textual analysis. It is very much useful in Natural Language Processing and Understanding.
As we have already discussed that it can be used in place for NLTK and spaCy library while working on unstructured data analysis. The TextBlob library is based on NLTK and thus adds more functions to the native work functions.
Features of TextBlob Library
It has similar features as spaCy and NLTK and the performance is a topic of debate. For different tasks, people choose one or the other libraries as per the convenience.
Here are some of the important features of TextBlob:
1. Part of Speech Tagging: It is the process of tagging parts of a sentence based on their definitions. They could be verbs, adjectives
2. Sentiment Analysis: Analysing the emotion behind the text content as a whole or as a part.
3. Noun Phrase Extraction: Extracting phrases whose head is a noun or pronoun.
4. Text Classification: Classifying text based on multiple factors.
5. Sentence Tokenization: Segmenting a sentence into parts.
6. Lemmatization: Finding the root words so as to define the context of each sentence correctly.
7. Correction of Spellings: Helping in correcting the spellings based on patterns and learning.
8. WordNet Integration: TextBlob makes it easier to integrate with WordNet which is a database of English language words.
9. n-grams: N-gram is a sequence of any N-words which helps in deciding the next word in a sentence. For more details, you can check An Introduction to N-grams.
10. Adding New Models or Languages through extensions.
TextBlob has got all the features that make it one of the best choices for NLP. In the next segment below we will be looking at the installation and implementation of TextBlob:
Installing TextBlob Library
Run these commands on either Anaconda prompt, Windows Command Prompt or within Linux Terminal to install TextBlob:
pip install -U textblob python -m textblob.download_corpora
If you are not provided with an error and everything is running well then TextBlob has been correctly installed on your environment.
We will be implementing all the features discussed above step by step. In the end, we will also have a look at a simple application of Sentiment Analysis with TextBlob.
All these coding part is done with Jupyter Notebook but you can choose any other IDE if you want. Let’s get started now.
Implementation of TextBlob Library
1. Importing TextBlob
TextBlob could be imported into the environment simply by writing in the code below:
from textblob import TextBlob
2. Reading a Text Document with TextBlob function
We need to pass our text through the TextBlob function using this code:
tb1=TextBlob(" We are learning cool Library . We are enjoying a lot .")
tb1
Output Screen:
 |
| Reading a Text Document |
3. Tokenization
We can segment sentences and words with the help of Tokenization using the code below:
import nltk
nltk.download('punkt')
If it gives True as output that means ‘punkt’ has been downloaded. Then use .words or .sentences to get the results.
Output Screen:
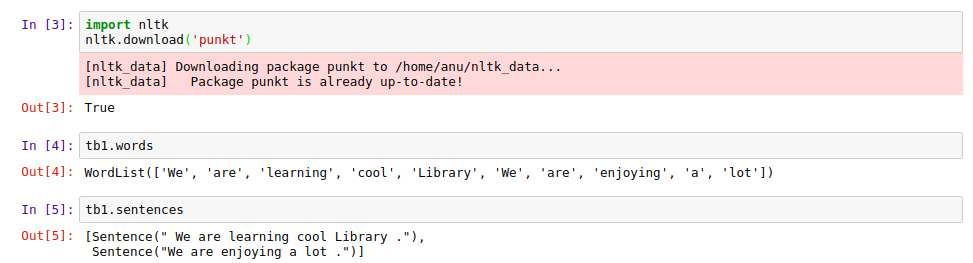 |
| Tokenization |
4. Working on Files with TextBlob
All the TextBlob features could be applied on Text files and we can see its implementation by the code below:
tb_file=TextBlob(file) print(tb_file.words) print(tb_file.sentences)
Output Screen:
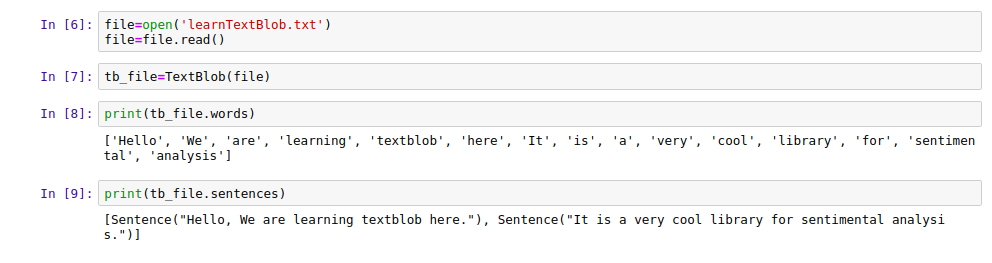 |
| Working on Files |
5. Part of Speech Tagging
Run the following commands to get Part of Speech:
import nltk
nltk.download('averaged_perceptron_tagger')
It will return true after downloading it correctly then you should be running the following commands to get the work done.
tb2=TextBlob("Tags will give the Part of speech for all the words.")
tb2.tags
For a complete list of P.O.S. tags you can check here: POS Tags
Output Screen:
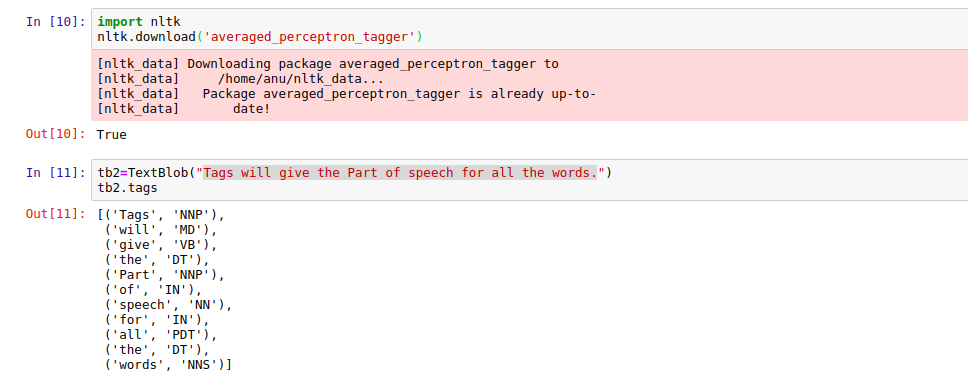 |
| Part of Speech Tagging |
6. Noun Phrase Extraction
Below are the commands you need to run in order to perform Nonu phrase extraction.
import nltk
nltk.download('brown')
tb3=TextBlob(" We are learning cool Library . We are enjoying a lot .")
tb3.noun_phrases
The output contains all the Noun phrases in WordList format.
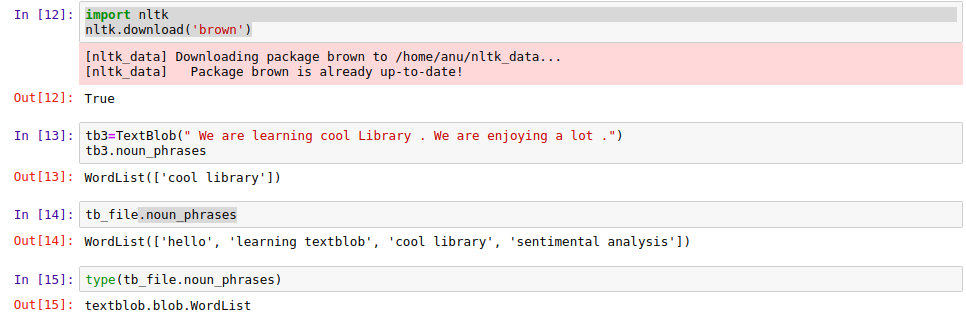 |
| Noun Phrase Extraction |
7. Counting Proper Nouns
You can easily count the proper nouns as such how many times they appear in the sentence by using ‘.np_counts’.
The command will return you the dictionary in with Noun as keys and their corresponding counts as values.
Here is the output for this code:
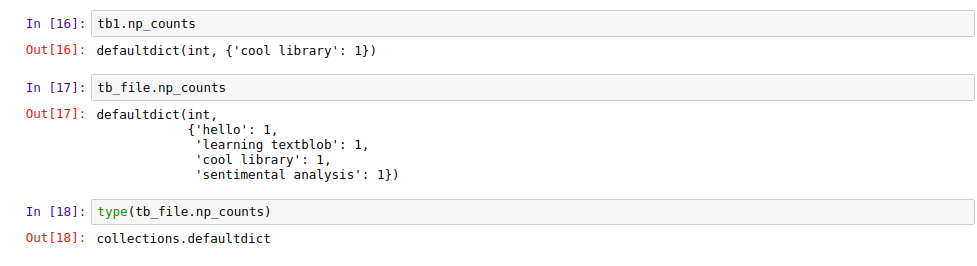 |
| Counting Proper Nouns |
8. Polarity
Polarity as discussed earlier helps us in finding the expression and emotion of the author in the text. The value ranges from -1.0 to +1.0 and they contain float values.
Less than 0 denotes Negative
Equal to 0 denotes Neutral
Greater than 0 denotes Positive
A value near to +1 is more likely to be positive than a value near 0. The same is in the case of negativity.
doc2=TextBlob("We are having fun here")
doc2.polarity
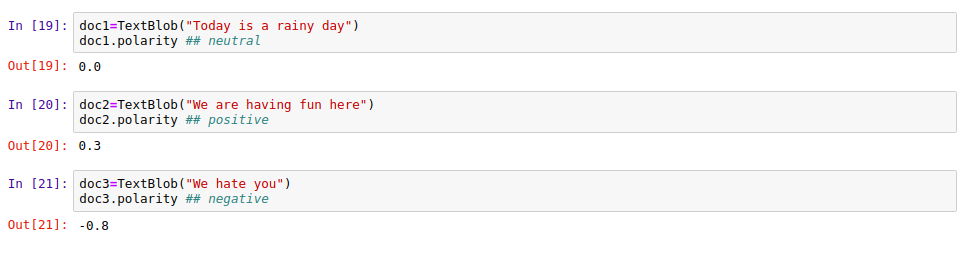 |
| Polarity |
9. Subjectivity
We have already discussed subjectivity in this article above. It helps us to check whether a sentence is subjective or objective. The value ranges from 0.0 to +1.0
Subjective sentences are based on personal opinions, responses, beliefs whereas objective sentences are based on factual information.
Let’s check this on the documents we have created:
doc2.subjectivity
 |
| Subjectivity |
10. Sentiment Analysis
The polarity and subjectivity score could be called together by .Sentiment command:
 |
| Sentiment Analysis |
11. Language Translation
TextBlob gives an amazing feature to translate sentences from one language to another. Check the corresponding shortcut value of any language from here Google Translate
 |
| Language Translation in TextBlob |
12. Spelling Correction
One of the most useful features of the TextBlob library is the Spelling Correction. Use the ‘.coorrect( )’ function to enter in the text and get a completely correct text in return with all the spellings fixed.
You can also use the ‘.spellcheck( )’ function to get all the possible correct values for wrongly spelled words.
w1 = Word('correct')
w2 = Word('corct')
print(w1.spellcheck(),w2.spellcheck())
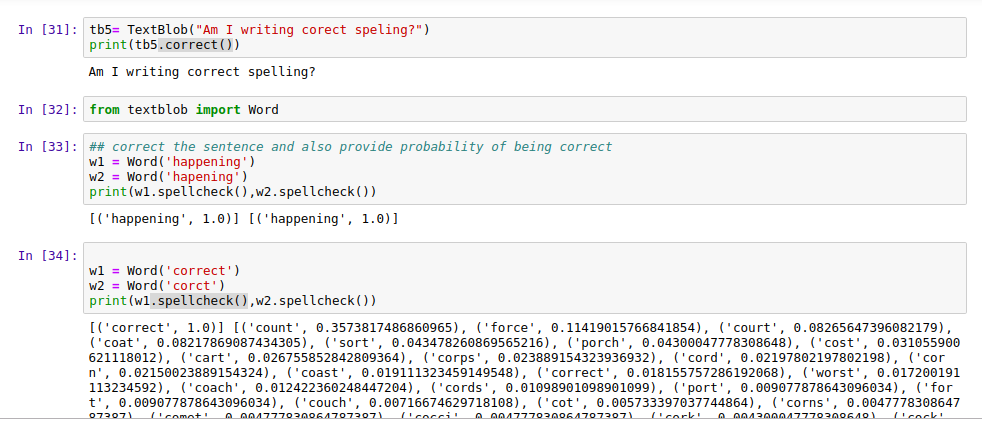 |
| Spelling Correction using TextBlob |
13. TextBlob n-grams
As told earlier n-grams are the n-words in a sequence which helps in deciding the next words probably. This has great application in word suggestion tools which are also used in Search engines.
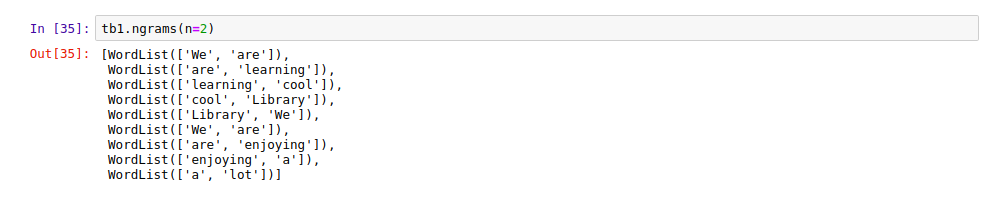 |
| N-Grams using TextBlob |
14. Words Inflection
Using this feature we can find the singular or plural form of any word.
tb4 = TextBlob('Children are playing with ball.')
print(tb4.words)
print(tb4.words[0].singularize())
print(tb4.words[-1].pluralize())
Output Screen:
 |
| Words Inflection |
15. Lemmatization
Another important feature of the TextBlob library to perform on the text. It can be used to find the root word for any given word.
We will need to import ‘wordnet’ package from the NLTK library as follows:
import nltk
nltk.download('wordnet')
Then run the following commands to perform lemmatization:
from textblob import Word
w = Word("played")
wl=w.lemmatize("v") # Pass in WordNet part of speech (verb)
print(wl)
Output Screen:
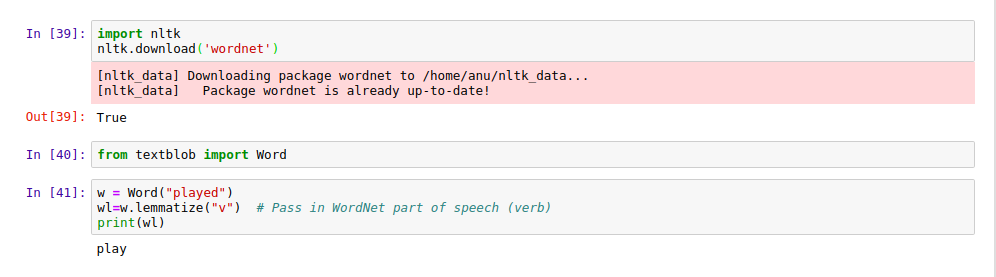 |
| Lemmatization |
16. Word Counts
Frequency of any word could be counted in any sentence:
tb6 = TextBlob("A Boy is playing football with another boy. "
"The team of football only include boys.")
tb6.word_counts['boy']
Output Screen:
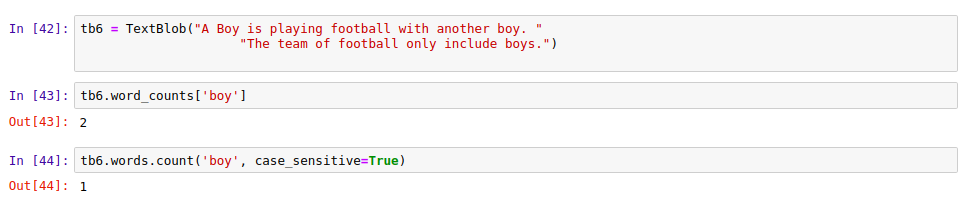 |
| Counting Words with TextBlob |
17. Sentiment Analysis with TextBlob
Now let us check a simple application of TextBlob in Sentiment Analysis. Here we have provided three texts as input and we will be finding out the total sentiment in the text bits.
document=['Today is a great weather . I love to go out . I want to have a lot of fun there.', 'My family is making a trip to hilly area. But i hate mountains . So i do not want to go there.', 'We went to a Cafe . The food was delicious . But the staff was bad.', ]
for m in document:
print("overall sentiment== ",TextBlob(m).polarity)
print('*************************************************')
for s in TextBlob(m).sentences:
print(s,s.polarity)
print()
The Output will look something like this:
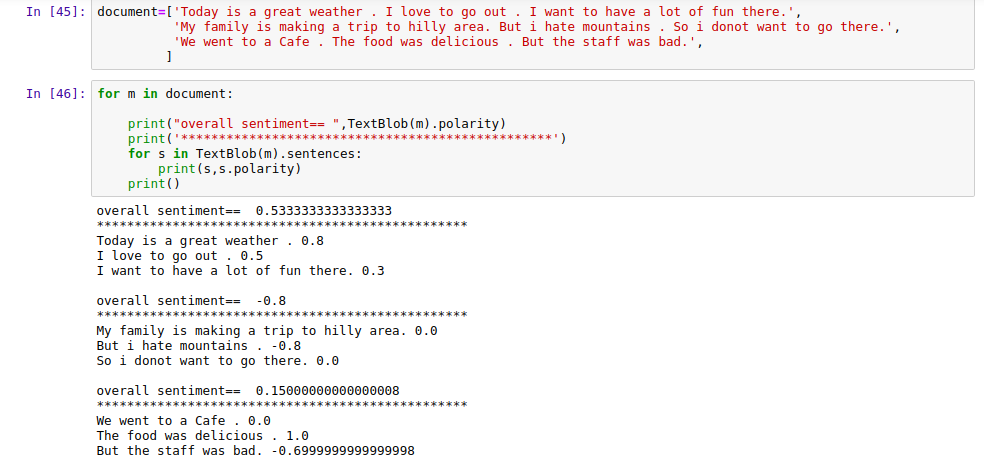 |
| Sentiment Analysis with TextBlob |
This was all about Sentiment analysis and how TextBlob can easily implement for performing it. For Complete code, you can access the GitHub TextBlob link.
We hope you liked the article, do comment down if you face any difficulty in using the library or the code segments.