
According to a research paper by Anthony Cocciolo from Pratt Institute, Textual data on the internet is decreasing gradually.
He told in the research paper as We may believe that online users are not interested much in textual data anymore. Right from the year 1990, they have researched that text content on websites is decreasing year by year.
More and more websites are using ways to provide content in smaller bits. These smaller text bits could be used with Images, Videos, Infographics to convey messages in a shorter context.
These facts give emphasis to the need for a process known as Text Summarization. We will look into its definition, applications, and then we will build a Text Summarization Python algorithm with the help of the spaCy library.
What is Text Summarization?
As the above discussion might have already provided you with an image of a textual summary. It is a technique to convert a long piece of content into a shorter one without removing the actual context.
With the help of this technique, A summary of any text material could be generated. It only removes text data which does not change the overall meaning of the content.
One practical example of it is with mobile application Inshorts, This application provides 60 words News summary. It only contains Headlines and important facts rather than varied opinions.
It has a greater scope of application in the scientific research field. As there are research papers containing thousands of pages having important documentation. Text Summarization could help scientists in focusing only on the key phrases from all that data.
In earlier times it was manual work to produce a summary of textual content. With the advancement in artificial intelligence and Natural Language Processing techniques it is much easier to perform the task.
In this article, we will be using one such advanced Python library named spaCy. With the help of spaCy library, it becomes very much easy to dig out important information from tons of text data.
Types of Text Summarization
There are no fixed guidelines for categorization of the techniques that we use for it. Although for performing tasks in an organized way they are generally be divided into these following types:
1. Short Tail Summarization: In this type of summary the input content is very short and precise. Even after having a short length it needs to be summarized in such a way that it could be bounded further without any change in its meaning.
2. Long Tail Summarization: As you might have already grasped by the name. The content here could be too long to be handled by a human being alone. It could contain text data from thousands of pages and books at once.
3. Single Entity: When the input usually contains elements from just one source.
4. Multiple Entities: When the input contains elements from different document sources. This is one of the most useful applications of this technique.
5. General Purpose: In this type of Text Summarization Python has no attribute for the type of input is provided. The algorithm does not have a sense of the domain in which the text deals. It is performed after multiple training of algorithms on various types of textual content.
6. Domain-Specific: They are performed under a specific domain each time. For example, a Text Summarization algorithm that summarizes the Food recipe in just a few words. So it does have a domain of Food recipes and knows the context behind the data.
7. Informative Summarization: This summary keeps all the information related to the actual content. No change in meaning is seen in the output results.
8. Headlines Generation: News channels and applications use this type of summary. Headlines are generated according to the text content of an article.
9. Keyword Extraction: Only the most important keywords and phrases are extracted from the whole data. For example, extracting the phrases where some verbal conversation is going on and leaving all the narrations behind.
These were just a few of the types and for further explanation, you can check the article here:
We can create Python algorithms from any of the above-explained types with the help of the spaCy library. There are basically two techniques to build the final Text Summarization spaCy Model using Python language.
Below is the simple explanation for both of these techniques:
- Extractive Technique: In this technique, the important phrases from the actual content are taken together to build a simple and short summary.
- Abstractive Technique: Builds a summary with new phrases and words but keeps the original meaning alive.
Human beings generally use the Abstractive method to summarize something. We use words that we are more familiar with but there is one problem with the summary created by human beings. They never come up with a neutral one and the essence of their opinion could be easily seen in the final output.
Machines are better at doing this task because they do not have their own opinion. They just work on the pattern and training we have provided and take decisions with Artificial Intelligence that they have gained.
Applications of Text Summarization
1. News: There are multiple applications of this technique in the field of News. It includes creating an introduction, Generating headlines, Embedding captions on pictures.
2. Scientific Research: Algorithms are used to dig out important information from Scientific research papers. AI is outranking human beings in doing so.
3. Social Media Posting: Content on Social media is preferred to be concise. Companies use this technique to convert long blog articles into shorter ones suited for the audience.
4. Creating Study Notes: Many applications use this process to create student notes from vast syllabus and content.
5. Conversation Summary: Long conversations and meeting recording could be first converted into text and then important information could be fetched out of them.
6. Movie Plots and Reviews: The whole movie plot could be converted into bullet points through this process.
7. Deliverable Feeds: They are the short piece of information derived from the complete informative articles. These are generally delivered to people through emails or feed delivery services.
8. Content Writing: Not from the scratch though but on providing a topic and points an outlined summary could be generated.
Although there are hundreds of other applications we just limited them to a few main topics.
Text Summarization in Python With spaCy
We will be building some Python algorithms for performing the basics of automated Text Summarization.
The spaCy library is our choice for doing so but you could go with any other Machine Learning library of your choice.
We have already written an article on the complete implementation of the spaCy library you can read it in our blog.
1. Importing the Library
import spacy from spacy.lang.en.stop_words import STOP_WORDS from string import punctuation
Here spacy.lang.en contain English stopwords. Similarly, you can access stopwords for any language using its extension such as ‘en‘ is for the English Language.
2. Getting data
extra_words=list(STOP_WORDS)+list(punctuation)+['\n']
nlp=spacy.load('en')
doc = """Your Text Content Here"""docx = nlp(doc)
 |
| Getting Data for Text Summarization |
spacy.load(‘en’) is used to load the object for the English language. extra_words is created to hold all the stop words and punctuation.
We have used the text about NLP from Algorithmia but you could choose any text material that you have.
3. Creating Vocabulary with spaCy
All the extra words are removed and the count of each other word is entered into the dictionary.
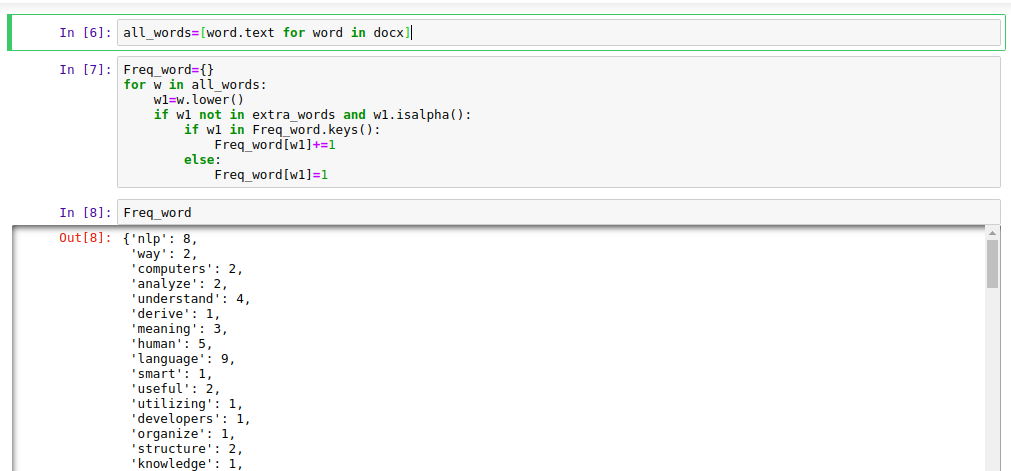
all_words=[word.text for word in docx]
Freq_word={}
for w in all_words:
w1=w.lower()
if w1 not in extra_words and w1.isalpha():
if w1 in Freq_word.keys():
Freq_word[w1]+=1
else:
Freq_word[w1]=1
Output Screen:
 |
| Creating Vocabulary |
4. Assigning a Title – Headline Generation
With the help of spaCy, we can actually find titles of the content that we have entered. This way it could be implemented for Headline generation.
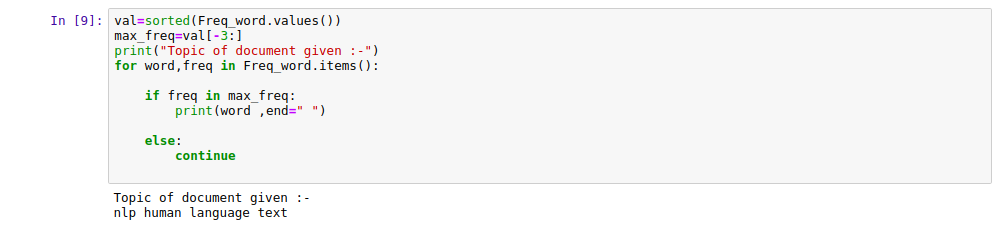
val=sorted(Freq_word.values())
max_freq=val[-3:]
print("Topic of document given :-")
for word,freq in Freq_word.items():
if freq in max_freq:
print(word ,end=" ")
else:
continue
Output Screen:
 |
| Headline Generation |
We got “NLP Human Language Text” as our title which is quite near to our text. It is not the best title but this is just the basic test of features provided by python library spaCy.
5. TFIDF
Short form for Term Frequency – Inverse Document Frequency, It is used to represent how important a given word is to a document on a complete collection relatively.
We can represent it with the code below:
for word in Freq_word.keys():
Freq_word[word] = (Freq_word[word]/max_freq[-1])
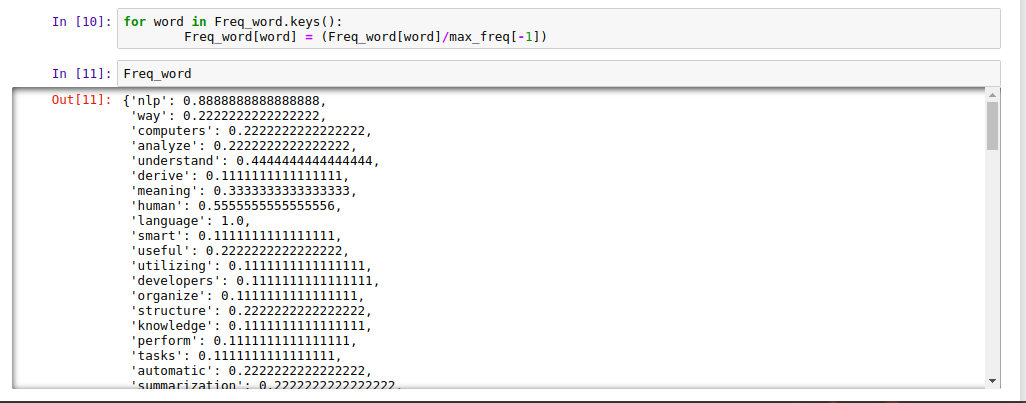 |
| Tf – Idf |
After getting the strength of each individual word we can have the strength of each sentence. This way we will get to know the importance of each sentence so that the sentences having no importance could be removed from the summary. Python Text Summarization is one of the best practice to go with.
6. Sentence Strength
The sentence with the most important words will have much more importance. We can find out this with the code below:
sent_strength={}
for sent in docx.sents:
for word in sent :
if word.text.lower() in Freq_word.keys():
if sent in sent_strength.keys():
sent_strength[sent]+=Freq_word[word.text.lower()]
else:
sent_strength[sent]=Freq_word[word.text.lower()]
else:
continue
Output Screen:
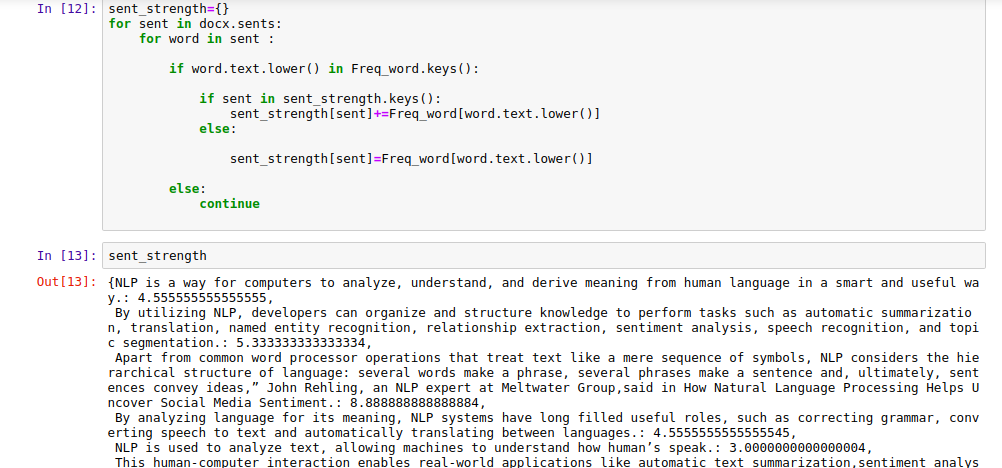 |
| Sentence Strength Calculation |
7. Getting Important Sentences
We will now be sorting the sentences according to their strength and choosing only according to the requirement. Sometimes the strength requirement is high for example in controversial topics it is better to choose all the important factors.
The code to perform this would be:
top_sentences=(sorted(sent_strength.values())[::-1]) top30percent_sentence=int(0.3*len(top_sentences)) top_sent=top_sentences[:top30percent_sentence]
8. Creating the Final Summary
Here the final summary is being created using only the valuable information. All the content which had less to none importance will be removed from the content.
We will be using the following code to perform this:
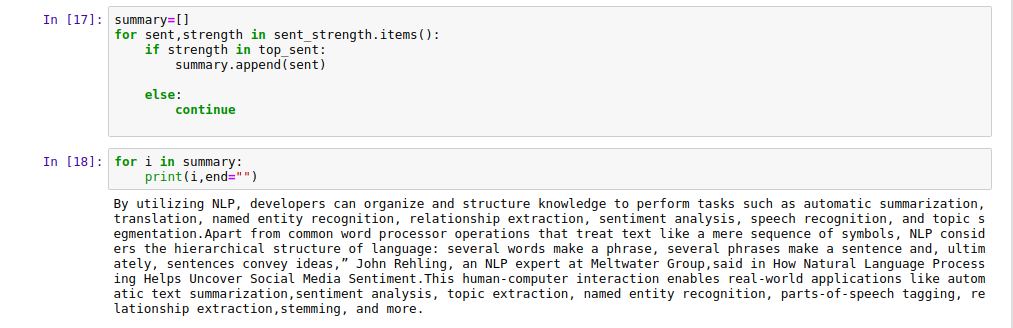
summary=[]
for sent,strength in sent_strength.items():
if strength in top_sent:
summary.append(sent)
else:
continue
for i in summary:
print(i,end="")
Output Screen:
 |
| Text Summarization in Python |
Here is our Text summary created in Python Language with the help of spaCy. If you want to learn Python Programming then do check out some free Python courses listed by us.
What are your words on this Summary?
It could be refined and made perfect with other spaCy filters that we will look at some time in our next tutorials.
For the complete code, you can check our GitHub repository
Leave your feedback down in your comments and try Text Summarization with spaCy on your own.
1 thought on “Text Summarization in Python With spaCy Library”